

What is Puppeteer?
Puppeteer is a JavaScript library from Google that allows developers to control Chrome via an API.
A common use case is using Puppeteer for testing, where we can make sure that actions we perform in the browser work as we expect them to.
But we can also use it to automate tasks that we want to programmatically perform in the browser. For instance, we can use Puppeteer to launch a website in Chrome and get it’s lighthouse score (see the example from the Puppeteer team).
How can we use Puppeteer in a serverless function on Netlify?
Puppeteer works both with opening a visible browser UI and “headless”, meaning, it will run as a process without actually launching the UI.
This makes it great for running in places you might not have a browser UI to open like CI environments and like you might have guessed, serverless functions.
So we can take advantage of this capability allowing us to build API endpoints that can perform an action using Puppeteer.
What are we going to build?
We’re going to use Netlify to create a new serverless function that we’re able to POST a request to via an API endpoint.
In this, we’ll learn how we can take advantage of packages like chrome-aws-lambda and Puppeteer itself to package all of this up in a serverless function that can run on request.
We’ll use the Netlify CLI to work with our functions, but it should work pretty similarly however you run and package up your functions.
Step 0: Creating a new node project
For this project, we’re going to start from scratch, as there’s not much boilerplate needed for this.
The nice thing is because there’s not much boilerplate, this should really transfer to any project, so you should have no problem following along within your pre-existing project.
So to get started, let’s create a new directory for our project and navigate to it:
mkdir my-puppeteer-function
cd my-puppeteer-functionNote: feel free to use a different name for your project!
We’re then going to initialize a new node project so that we can install the packages we need to get ourselves productive.
To create a new node project, run:
npm initThis will go through a bunch of questions asking you how you want to set up your project. Feel free to hit enter for all of them and use the default as they’re not really important for this walkthrough.
Tip: You can always update these values in your
package.json!
At this point, we now have a new node project where we can start to get productive with our new project.
I’d also recommend setting up the project as a GitHub repository. When doing that, you want to make sure you add a .gitignore file in the root including your node_modules to avoid committing those.
To do that, create a .gitignore file in the root, and simply add:
node_modulesAnd now we should be ready to dig in!
Step 1: Installing and configuring the Netlify CLI
As I mentioned earlier, we’re going to use the Netlify CLI to manage our function. This will include installing the CLI as a global package via npm or yarn. If you want to a void this route, you can also try checking out netlify-lambda which you can install as a local package, but it may work a bit differently.
You can find the full instructions and documentation over on Netlify, but to start off, we want to install the CLI package:
npm install netlify-cli -gOnce installed, you should be able to run the following command and see a list of available options:
netlifyWhile this alone will allow you to start using the CLI, I also recommend you log in using your existing Netlify account.
This will allow you to more easily link your project up later whenever you want to deploy your function.
You can do this by running:
netlify loginWhere Netlify makes this process super easy, opening up a new browser window, where you can authorize with your account, where you’ll then be authorized with the CLI.
You can also try running the following:
netlify devWhich should start a local server, but you’ll notice it won’t do anything yet, as we have nothing in the project, which is where we’ll start next!
Step 2: Creating a new serverless function
Now to start digging into the code, we want to set up a new serverless function.
We have to parts to this:
- The function itself including the file and the function handler
- The Netlify configuration file (
netlify.toml) which simply allows us to point to a directory where we want to create our functions
Starting off with creating the function file itself, let’s create a new folder called functions in the root of our project and inside, add a new file called meta.js (our first example will be grabbing some metadata from a webpage).
Note: prefer a different directory name than “functions” feel free to use something else, just be sure to use that same name in the rest of the walkthrough.
Inside functions/meta.js add:
exports.handler = async function(event, context) {
return {
statusCode: 200,
body: JSON.stringify({
status: 'Ok'
})
};
}This creates a new asynchronous function that will serve as our “handler” which essentially runs whenever we hit the endpoint.
Inside, we’re returning a 200 status code, meaning it was a successful request, and a body with a simple status that says “Ok”.
Now before we can use it, we need to create our configuration file.
Create a new file called netlify.toml in the root of the project.
Inside netlify.toml add:
[build]
functions = "functions"This tells Netlify that we want to create our functions in the folder called “functions”!
And now the moment we’ve been waiting for.
We can start up our development server and see this work!
Run the following command:
netlify devYou should see a few lines in the terminal stating that the CLI found your functions and started a server at the specified port (default is 8888).
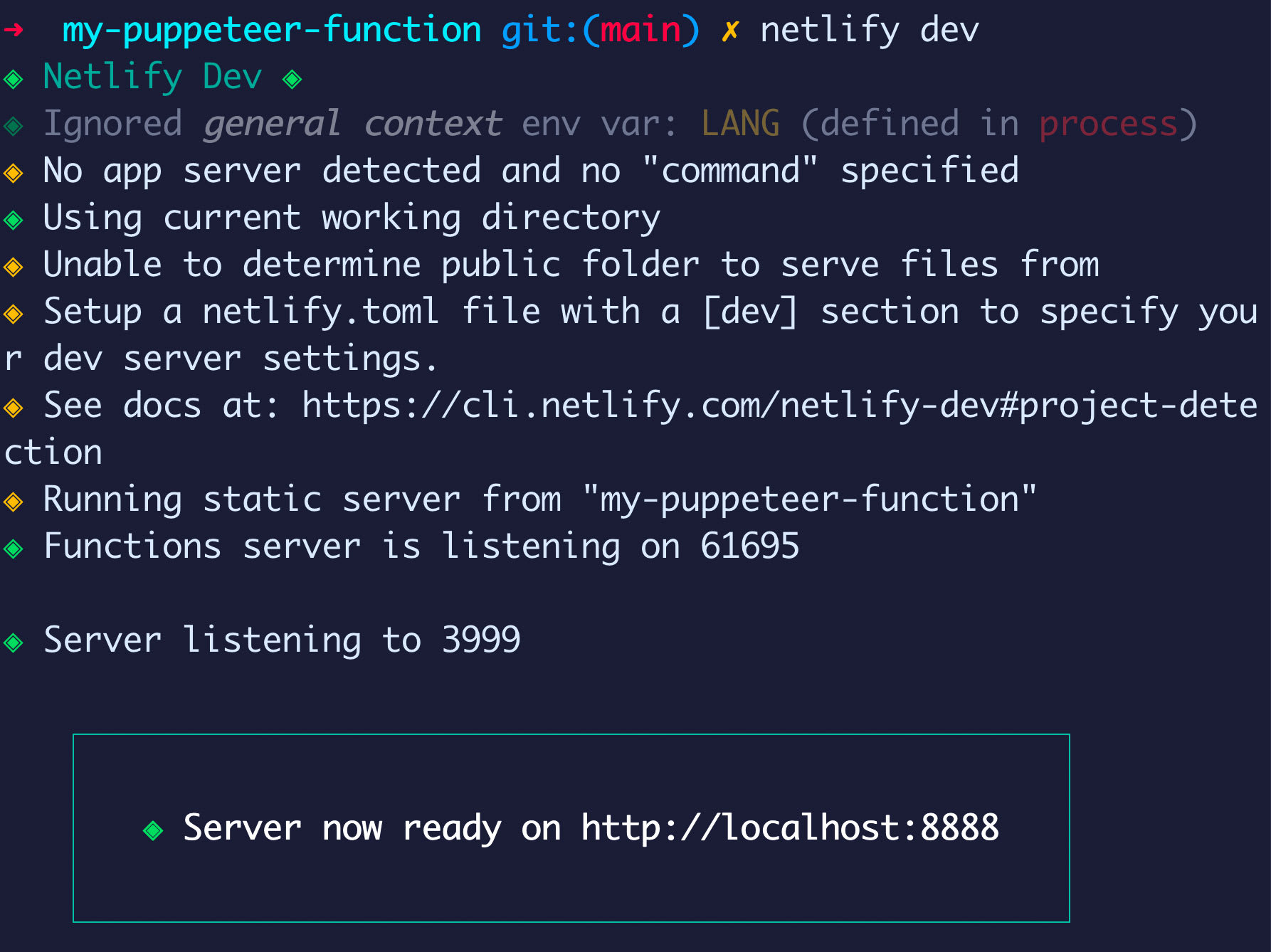
Netlify will even try to open that in the browser, though it won’t find anything as we don’t have any projects to show.
However, if we try going to http://localhost:8888/.netlify/functions/meta, we should see a JSON response in our browser!

While this doesn’t seem like a whole lot, we just created a new API endpoint where we can start writing custom code!
Step 3: Installing Chrome and Puppeteer to use in a serverless function
We have our new serverless function, we were able to see it running in the browser, now we need to install the tools required to run Chrome and Puppeteer inside.
We’re going to use two dependencies for this:
Psst: technically we’re going to use a third, but we’ll see why a bit later!
Our serverless functions don’t have Chrome available by default and we don’t really have a mechanism to “install” it either. chrome-aws-lambda packages up the Chromium Binary so that we can use it as a node package along with the other dependencies of our project.
puppeteer-core is the driving functionality of Puppeteer, but the big difference between it and the standard puppeteer package is it doesn’t come with browsers. Because we need to provide our own via chrome-aws-lambda, we don’t want to try to add the extra browsers to our bundle, as we’re limited by file size in a serverless function.
So now that we know why we’re using these packages, let’s install them.
yarn add chrome-aws-lambda puppeteer-core
# or
npm install chrome-aws-lambda puppeteer-coreAnd once complete, we’re ready to dig into the actual code!
Step 4: Setting up a new browser with Puppeteer to get a page’s title and SEO metadata
To get started, we need to first import our dependencies.
At the top of functions/meta.js add:
const chromium = require('chrome-aws-lambda');
const puppeteer = require('puppeteer-core');Next, the way Puppeteer works, is we create an instance of a browser by associating it with the installed copy of the browser (Chromium) and launching it.
Add the following at the top of the handler function:
const browser = await puppeteer.launch({
args: chromium.args,
executablePath: await chromium.executablePath,
headless: true,
});
await browser.close();We’re using Puppeteer’s launch method to pass in flags from our instance of Chromium, an executable path (where the browser app launches from) which the chromium package is able to find and determine, along with the headless flag set to true as we don’t want to try to launch a UI.
Notice at the end, we’re also using the close method. We want to make sure we’re always cleaning up our browser to avoid hanging requests and wasted resources.
Now before we go further, let’s just make sure things are working. When we start this up, we’re not going to see anything actually “happen” as it’s running headlessly and we’re not doing anything with it, but we don’t want to see any errors either
In your terminal, run:
netlify devThen try opening up the function in your browser at http://localhost:8888/.netlify/functions/meta.
Uh oh, you’ll notice that we actually get an error!
Unfortunately, chrome-aws-lambda doesn’t “just work” when trying to run locally. While this should work if you deploy it as is to Netlify, it won’t do us much good if we can’t test it locally while we develop it.
The good news though, is we can override our executable path when running locally to use our existing Chrome installation by using an environment variable!
Note: chrome-aws-lambda has a workaround to run projects locally installing puppeteer as a dev dependency, I didn’t have much luck getting that to work myself.
To start, we’re going to use the popular dotenv package which make this easy to set up. In your terminal run:
yarn add dotenv
# or
npm install dotenvNext, inside of functions/meta.js, update the executablePath to:
executablePath: process.env.CHROME_EXECUTABLE_PATH || await chromium.executablePath,This is telling Puppeteer that we want to we first want to try to see if we have an environment variable set (locally) and if we don’t (production) try to find the path to Chromium.
Now we need to set that environment variable.
In the root of your project, create a new file called .env and add:
CHROME_EXECUTABLE_PATH="/path/to/chrome"Now is can be the tricky part, finding this path.
Luckily, Chrome makes this somewhat easy. If we go to chrome://version/ in our browser, we should be able to find a field called Executable Path, which is exactly what we need!
Here’s what this looks like for me on my Mac:

So now, we can plug that value into our environment variable:
CHROME_EXECUTABLE_PATH="/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"And if we restart our development server so that variable kicks in, we should now be able to refresh the endpoint in our browser ans see our “Ok” status again!
Note: before we move on, make sure to also add
.envto your .gitignore file as we don’t want to push this to the repository.
Now with our browser, we can start our Puppeteer interactions by creating a new page and navigating to our website of choice.
Add the following below the browser constant:
const page = await browser.newPage();
await page.goto('https://spacejelly.dev/');Note: feel free to customize the URL to whatever you’d like!
If we try to run it, we still won’t see anything happen. Let’s fix that by finding the page title and returning it with our data.
After we navigate to our website of choice, add:
const title = await page.title();And inside of our return statement, add the following as a new property under the status:
body: JSON.stringify({
status: 'Ok',
page: {
title
}
})This will tell Puppeteer to get the page’s title and then return it in our response.
And now if we refresh the page in our browser, we should see our page title!

We can even extend this as much as we want using the Puppeteer API. For instance, if we also wanted to grab the meta description, under the title we could add:
const description = await page.$eval('meta[name="description"]', element => element.content);Note: there’s no native API to get the description like there is the title, so we need to find the tag and evaluate it manually
And like before, return it in our data:
page: {
title,
description
}Where if we refresh our browser, we should now see both the title and the description!

Step 5: Using a website’s search to find content
The cool thing about Puppeteer is we have a ton of capabilities with it. We can interact with pages and really do a lot of things an actual human would do on a webpage.
To test this out, let’s try an example of making a search on spacejelly.dev and grabbing the list of results.
We’re going to start offur m by duplicating our current endpoint and creating a new one to work with.
In your project, copy functions/meta.js to a new file functions/results.js.
Most of the shell of the file will be the same, as we’re going to create a new browser just like we did with our metadata, only this time, instead of grabbing the title and description, we’re going to search the page!
To start, inside functions/results.js replace the title and description lines with:
await page.focus('#search-query')
await page.keyboard.type('api');
const results = await page.$$eval('#search-query + div a', (links) => {
return links.map(link => {
return {
text: link.innerText,
href: link.href
}
});
});This will focus the browser on the search input then type the query “api”, which will pop up the search results clientside.
Once that’s available, we can find those results and evalute them, grabbing the text inside of the link and the location, storing it in a results variable.
So finally, let’s return that with our data. In our return statement, add:
return {
statusCode: 200,
body: JSON.stringify({
status: 'Ok',
results
})
};And now with our development server running, if we hit the endpoint, we should see our results!

Step 6: Deploying the functions to Netlify
Finally, we want to see this work on production, so let’s get it deployed to Netlify.
Because we’re using the Netlify CLI, this is actually pretty easy to do right from our terminal!
To start, run:
netlify deployIt will first ask if you want to link to an existing project or create a new one. If you’re following along, you’d likely want to create a new one. If you’re in an existing project, you’d probably want to follow along with what you already have.
You’ll then select your Netlify account’s team and a site name. You’ll also be asked for a Publish Directory which again, if you’re following along, you can use the default directory of ., so just hit Enter.
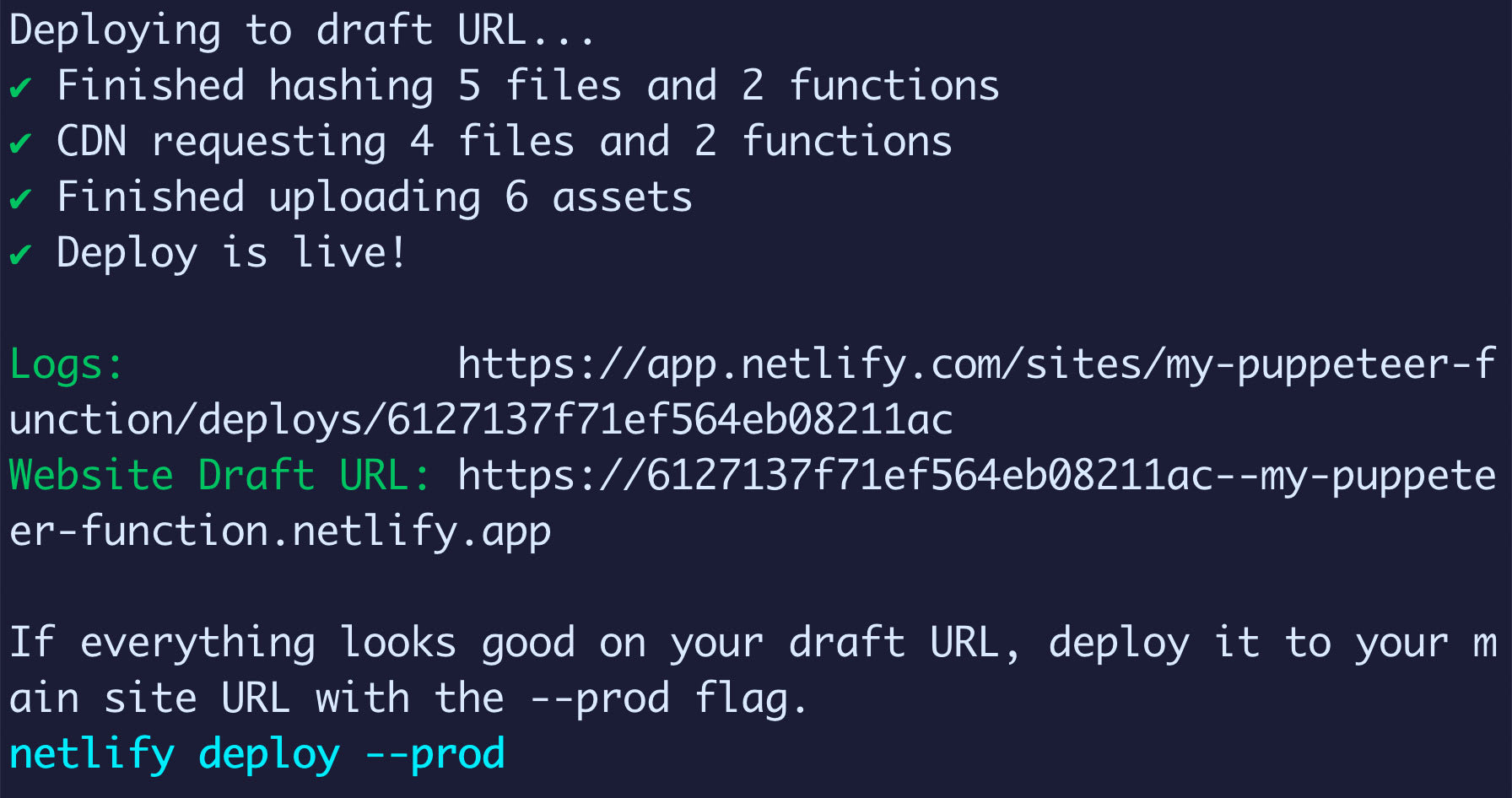
At this point, Netlify only deployed a Preview, which you can check out at the Website Draft URL.
To see that, we can take that URL and append the path to the function. In my example shown in the screenshot above, that would look like:
https://6127137f71ef564eb08211ac--my-puppeteer-function.netlify.app/.netlify/functions/metaThis should work just like it did locally!
Note: I deleted my deployment, so the above link won’t actually work!
And if we’re ready to go, we can deploy that to production using:
netlify deploy --prodWhere once finished, we can now see our new serverless function using Puppeteer and Chrome deployed to Netlify!
What can you do next?
Moar Puppeteer
There’s a lot to try out with the Puppeteer library. If you can do it in a browser yourself, likely you can figure out a way to do it with Puppeteer.
This makes it really great for things like tests where maybe you want to make sure a particular part of the website is working and you want to do that via an endpoint. Or if you want to do some web scraping to grab live data from a website. (Make sure to be ethical! ????)